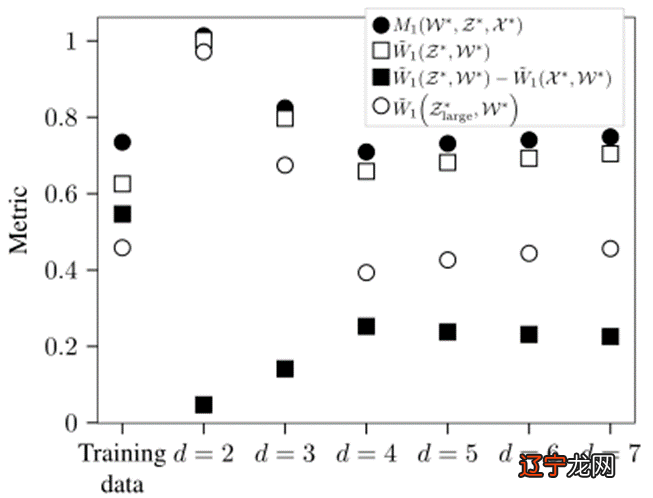
为了证明的选择是合理的 , 图11显示了所提出的指标的中值与不同值的之间的相关性 。 , 即 , 针对LVD场景的相关性为0.974 , 针对切入场景的相关性为0.824 。相关性随着的增加而增加 , 直到 LVD 场景的和切入场景的处获得最大相关性值(0.992 和 0.987) 。增加会进一步降低相关性 , 这表明选择是合适的 。
文章插图
图9 Nw=10000个LVD场景参数集的指标中值

文章插图
图10 Nw=10000个Cut-IN场景参数集的指标中值
在给出的初始选择(用表示)的前提下 , 可用以迭代方式确定和:
设置
确定 , 即使用 最小化 的最佳参数数量
生成 和 , 其中
将 增加 1
通过最大化 两者之间的相关性来确定 ,如图11所示
重复步骤2 7)如果 结束 , 否则返回步骤3 。

文章插图
图11 和 的相关性
作为初始选择 , 是合适的 , 更具体地在时 , 在一次迭代之后寻找的最佳选择 。
Ⅵ.讨论
本研究提出生成场景参数的方法的优点之一是对场景参数化较少假设:
不需要对时间序列数据的预定函数形式进行假设 。例如 , 在LVD场景中 , 通常假设速度遵循多项式函数[10]、正弦函数或线性函数[21] 。在预定函数形式的情况下 , 将参数拟合到函数形式 。本研究中SVD自动确定参数化的最佳选择 , 而不依赖于预定的函数形式 。
不需要对参数分布进行假设 。例如 , 可以假设特定的分布 , 例如其它方法需要采用参数已拟合的高斯分布[29]或均匀分布 , 并且对参数的独立性做出假设[24] 。本研究中KDE自动调整其形状以适应数据 , 并考虑不同参数之间的依赖性 。
如果有理由相信一个或多个假设是有效的 , 那么利用这些假设生成场景参数的方法可能比本研究提出的方法效果相同或更好[51].但是在大多数情况下 , 很难对有关函数假设(例如 , 车速)和场景参数的PDF 提供明确的证明 。在任何情况下 , 本研究提出的SR指标适用于基于任何假设的有关场景参数化和参数分布研究 。
生成的场景参数代表现实生活中可能发生的场景 , 涵盖了与现实世界交通相同的多样性 。最有可能的是 , 这些场景中的大多数对于自动驾驶汽车来说较为简单 。为了进行有效的评估 , 重点应该放在可能导致碰撞概率很高的危急情况的场景上 。这就是为什么所谓的重要性抽样 [52 , 第5.6章] 经常用于评估自动驾驶汽车的性能 , 例如 , 参见文献[5]、[10]、[53]、[54] 。通过重要性抽样 , 使用不同的PDF 对场景参数进行采样 , 从而更好的构建可能导致危急情况的场景 。为了获得无偏的结果 , 使用场景参数x的测试结果按原始概率密度 与用于重要性采样的PDF概率密度[10]的比率加权[52]-[54] 。在未来的工作中 , 我们生成场景的方法将与重要性采样[10]、[53]、[54]相结合 , 以评估 自动驾驶汽车性能 。
在某些情况下 , 可能希望从条件PDF中进行采样 , 例如 , 在对LVD场景的参数进行采样 , 使得初始时间间隔等于指定值 。从KDE中采样以便预先确定一个或多个参数是直接的 [55] 。本研究的例子中 , 从采样使得时间间隔等于指定值会导致对样本的线性约束 , 因为(公式10)的缩减参数向量来自原始参数的线性映射(公式2)的 , 即从 (公式11) 的中采样 , 使得 受线性约束
以上关于本文的内容,仅作参考!温馨提示:如遇专业性较强的问题(如:疾病、健康、理财等),还请咨询专业人士给予相关指导!
「辽宁龙网」www.liaoninglong.com小编还为您精选了以下内容,希望对您有所帮助:- 什么是自动清算所
- 近万元的匹克鞋!《流浪地球》加持,3D技术+自动系带,匹克芜湖起飞?
- 汽车年检需要多少钱 年检需要多少钱
- 北京汽车过户需要什么手续 2022年详细流程
- 汽车保险怎么买?
- 汽车如何检修正时链条和链轮?
- 1 考虑关于清洁空气和汽车运输来自的生产可能性边界。 解释为什么未被管制的汽车尾气污染会使国婷间解语可都稳陆甚将民经济处在生产可能性之内...
- 机械设计制造与自动化专业具体学习什么课程?
- 养车小知识,汽车保险怎么买合适?
- 预付费智能电表一户一表、远程自动抄表、电费预充值-安科瑞黄安南